Executive Summary
Das Problem: Die Vertrauenslücke (Trust Gap)
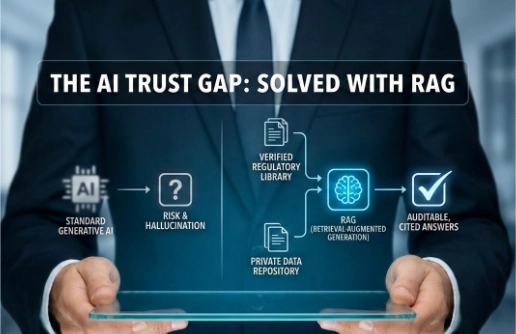
Obwohl Generative KI Consulting revolutionieren soll, stoßen regulatorische Professionals auf ein zentrales Problem: Halluzinationen. Standard‑KI‑Modelle sind „Closed‑Book“-Denker; sie verlassen sich auf ihr Gedächtnis – was zu erfundenen Regulierungen und nicht verifizierbaren Empfehlungen führt. In einem Umfeld, in dem eine falsch zitierte Klausel eine Haftung auslösen kann, ist „meistens korrekt“ nicht gut genug.
Die Lösung: Retrieval‑Augmented Generation (RAG)
RAG ist das „Sicherheitsventil“, das KI von einem kreativen Autor in einen disziplinierten Research Assistant verwandelt. Statt die KI raten zu lassen, zwingt RAG das System, zuerst eine private, verifizierte Bibliothek Ihrer Dokumente – Gesetze, Policies und Audit‑Reports – zu durchsuchen, bevor es antwortet. Es verlässt sich nicht auf das, was es „im Internet gelernt“ hat, sondern auf die „Golden Source“‑Daten, die Sie bereitstellen.
Zentrale strategische Vorteile:
- Chain of Evidence: Jede KI‑Antwort enthält eine direkte Quellenangabe (Seite/Absatz) zum Originaldokument. Verifikation dauert Sekunden, nicht Stunden.
- Data Sovereignty: Im Gegensatz zu öffentlichen Bots hält Enterprise‑RAG sensible Daten innerhalb Ihrer Firewall. Die KI liest Ihre Daten, um Fragen zu beantworten, „lernt“ jedoch nicht daraus und leakt nichts in die Öffentlichkeit.
- Sofortige Dokument‑Aktualität: Das System ist so aktuell wie Ihr letzter Upload. Wenn um 9:00 eine neue Direktive veröffentlicht wird, ist Ihr RAG‑System um 9:01 Experte dafür.
- Bottom Line:
RAG‑Systeme ermöglichen es Compliance Officers, Compliance‑Consultants und Auditoren, die Lücke zwischen KI‑Effizienz und regulatorischer Präzision zu schließen. Sie automatisieren die Vor‑Synthese komplexer Aufgaben und liefern vertrauenswürdige, zitierte Outputs, die Stunden manueller Suche eliminieren und evidence‑basierte Entscheidungen beschleunigen.
I. Einführung
Die Adoption von Generative AI im Compliance‑Umfeld ist bemerkenswert schnell vorangeschritten. Die meisten Professionals haben Tools wie Gemini, ChatGPT oder Claude bereits in ihre täglichen Workflows integriert – etwa um Korrespondenz zu entwerfen, lange Meeting‑Transkripte zusammenzufassen oder Projekt‑Outlines zu brainstormen. Doch während sich die Neuheit dieser Tools in Standardpraxis verwandelt, taucht für High‑Stakes‑Felder ein „Elefant im Raum“ auf: das Risiko von Halluzinationen.
Standard‑LLMs arbeiten probabilistisch, nicht deterministisch. Sie sind darauf optimiert, hilfreich und flüssig zu wirken – was gelegentlich dazu führt, dass sie zu „selbstbewussten Lügnern“ werden. In einem regulatorischen Kontext ist eine KI, die eine nicht existente Klausel erfindet, eine spezifische Jurisdiktionsanforderung fehlinterpretiert oder eine aufgehobene Direktive zitiert, nicht nur unhilfreich – sie ist ein Risiko. Deshalb bleiben viele Senior‑Compliance‑Leads zu Recht zurückhaltend, KI für kritische Advisory‑Arbeit oder komplexe Gap‑Analysen zu vertrauen.
Die Lösung für dieses Vertrauensdefizit liegt nicht darin, KI aufzugeben, sondern darin, grundlegend zu ändern, wie die Technologie auf Informationen zugreift. Hier wird Retrieval‑Augmented Generation (RAG) essenziell. RAG ist kein „neues Experiment“, sondern sollte als „Sicherheitsventil“ verstanden werden, das Generative AI erst für die Anforderungen regulatorischer Umfelder brauchbar macht.
Indem die kreative Power der KI an die verifizierten Daten einer Organisation gekoppelt wird, transformiert RAG die Technologie von einem unberechenbaren Autor in einen gewissenhaften, auditierbaren Research Assistant. Dieser Artikel zeigt, wie RAG als kritisches Control wirkt und Professionals in der regulatorischen Compliance ermöglicht, die Effizienz von KI zu nutzen – bei gleichzeitiger Wahrung der strikten Genauigkeit und Transparenz, die das Berufsfeld verlangt.
Was ist RAG?
Um Retrieval‑Augmented Generation (RAG) zu verstehen, hilft ein Bild: ein spezialisierter Bibliothekar arbeitet Hand in Hand mit einem Autor. In einer Standard‑Generative‑AI‑Interaktion verlässt sich das Modell vollständig auf seine internen Trainingsdaten – Informationen, die es „auswendig gelernt“ hat. RAG verändert diesen Prozess, indem die KI zuerst eine konkrete, kontrollierte Dokumentenbibliothek konsultieren muss, bevor sie eine Antwort formuliert. Da das System an diese Quellen gebunden ist, ist das Zurückverfolgen einer Antwort zur ursprünglichen regulatorischen Textstelle oder internen Policy unkompliziert und verifizierbar.
Im Gegensatz zu öffentlichen KI‑Tools, die aus dem riesigen und oft unzuverlässigen Internet schöpfen, operiert ein RAG‑System in einer nutzerdefinierten Umgebung. Dadurch entsteht ein geschlossener Informationskreislauf, der kontrollierbar und vertrauenswürdig ist. Für regulatorische Consultants bedeutet das: Die KI rät nicht mehr auf Basis allgemeiner Muster, sondern synthetisiert Informationen aus den exakten Versionen der Gesetze und Policies, die Sie bereitstellen.
Der mechanische Prozess von RAG lässt sich in drei Phasen gliedern:
- Retrieval: Nach Eingang der Anfrage scannt das System Ihr privates Repository – z. B. Direktiven, interne Audit‑Reports oder Jurisdiktions‑Frameworks – und identifiziert die relevantesten Passagen. Es liest nicht jedes Mal die gesamte Bibliothek, sondern die konkreten „Exhibits“, die für die Aufgabe notwendig sind.
- Augmentation: Die gefundenen Snippets werden mit Ihrer Frage kombiniert. Dadurch fokussiert sich die Verarbeitung der KI ausschließlich auf den bereitgestellten Text und erhält den nötigen Kontext, um korrekt zu bleiben.
- Generation: Die KI erstellt die Antwort ausschließlich auf Basis der zuvor abgerufenen Informationen. Diese architektonische Einschränkung ist zentral für Risikominderung: Fehlt die Information in Ihrer Bibliothek, sagt ein korrekt konfiguriertes RAG‑System, dass es die Antwort nicht findet. Das verhindert Fakten‑Erfindung und macht Dokumentationslücken sichtbar, statt plausible, aber falsche Aussagen zu liefern.
Der Kernwert: Warum Compliance RAG braucht
Der Wechsel von Standard‑KI zu RAG‑Systemen adressiert die drei größten Hürden für institutionelle Adoption generativer Technologie: Auditierbarkeit, Privatsphäre und Aktualität. Für Senior‑Consultants sind das keine rein technischen Spezifikationen, sondern Bausteine professionellen Risk‑Managements.
Genauigkeit und Auditierbarkeit
In Standard‑Generative‑AI‑Interaktionen erhalten Nutzer eine polierte Narrative, aber wenig bis keinen Nachweis der Herkunft. Das erzeugt eine Verifikationslast, die den Zeitgewinn häufig übersteigt. RAG löst das, indem es eine klare Chain of Evidence etabliert. Jede Aussage wird mit einer konkreten Quelle aus Ihrem Repository verknüpft. Wenn die KI eine regulatorische Anforderung behauptet, liefert sie ein Zitat – etwa Seite/Absatz im Rulebook oder einer internen Policy. Dadurch kann ein Consultant einen KI‑Draft in Sekunden verifizieren und die KI wird von einem kreativen Autor zu einem transparenten Research Clerk.
Data Sovereignty und Privatsphäre
Eine zentrale Sorge von Compliance‑Leads ist das „Leakage“ proprietärer oder sensibler Kundendaten in öffentliche KI‑Trainingssets. RAG‑Systeme in professionellen Kontexten laufen typischerweise unter einem Enterprise‑Framework, in dem Data Sovereignty Priorität hat. Ihre privaten Dokumente liegen in einer sicheren, isolierten Umgebung. Das Modell darf die Informationen „lesen“, um eine konkrete Anfrage zu beantworten, ist aber strikt daran gehindert, diese Daten zu „lernen“ oder für zukünftiges Allgemeinwissen zu behalten. So bleiben interne Audit‑Reports oder Kundenverträge innerhalb der digitalen Firewall Ihrer Organisation.
Schließen der Trainingslücke
Öffentliche KI‑Modelle haben eine Trainingslücke: Ihr internes Wissen ist auf den Zeitpunkt des Trainings eingefroren. In der Regulierung, wo eine Direktive von heute Morgen die gesamte Compliance‑Position verändern kann, ist diese Verzögerung inakzeptabel. RAG entfernt diese Einschränkung. Da das System beim Stellen der Frage aus einer Live‑Knowledge‑Base abruft, hat es keinen Cut‑off. Laden Sie die neueste EU‑Direktive oder SEC‑Filing hoch, wird das System sofort Experte dafür – ohne teures oder zeitintensives Retraining.
IV. Use Cases in der regulatorischen Compliance
Um die Effizienzgewinne durch RAG zu verstehen, lohnt ein Blick auf typische High‑Pressure‑Consulting‑Szenarien. Durch das Grounding in konkreten Dokumentsets können Firmen den „First Pass“ komplexer Aufgaben automatisieren, ohne die Standards für regulatorische Sign‑offs zu verlieren.
1. Regulatory Change Management
Wenn eine Regulierungsbehörde ein großes Update veröffentlicht – z. B. eine 200‑seitige Revision eines Operational‑Risk‑Frameworks – ist der manuelle Aufwand für eine Gap‑Analyse enorm. Ein RAG‑System kann das neue Dokument zusammen mit bestehenden internen Policies des Kunden nutzen.
Statt beide Dokumentsets von Grund auf zu lesen, kann ein Consultant fragen: „Vergleiche die neuen Operational‑Risk‑Anforderungen dieses Updates mit unserer aktuellen Internal Control Policy.“ Das System ruft die relevanten Abschnitte ab, identifiziert Abweichungen und markiert exakt, wo die aktuelle Policy die neuen Standards nicht erfüllt. Damit schrumpft die Research‑Phase von Tagen auf Minuten.
2. Automatisiertes Pre‑Audit und Control‑Validierung
Bei Audit‑Vorbereitung verbringen Consultants oft viel Zeit damit, festzustellen, ob konkrete Controls anhand voluminöser Dokumentation erfüllt sind. RAG ermöglicht einen automatisierten „Pre‑Audit“, indem eine Reihe control‑bezogener Fragen gegen das interne regulatorische Repository des Unternehmens ausgeführt wird.
Für jedes Control sucht das System nach Evidenz und trifft eine fundierte Einschätzung, ob das Control vollständig, teilweise oder nicht erfüllt ist. Entscheidend: Es liefert den exakten Text als Evidenz, sodass der Consultant die Einschätzung schnell validieren und sich auf Remediation der Gaps konzentrieren kann.
3. Regulatorische Klärung und Instant Advisory
Compliance‑Abteilungen werden häufig mit Routinefragen interner Teams (IT, HR etc.) überflutet. Beispiel: Ein IT‑Manager fragt: „Was ist die maximale Strafe für eine Datenpanne mit PII von EU‑Bürgern gemäß dem neuesten DSGVO‑Stand?“
In einer RAG‑Umgebung rät das System nicht auf Basis generischer Trainingsdaten. Es ruft sofort die relevanten Artikel aus dem aktuellen DSGVO‑Text sowie die konkreten Data‑Handling‑Policies des Unternehmens ab. Danach liefert es eine direkte Antwort – z. B. „bis zu 20 Mio. € oder 4 % des weltweiten Jahresumsatzes“ – und versieht sie unmittelbar mit Quellenzitaten (z. B. „Quelle: DSGVO Art. 83, Abs. 5, und interne Policy 4.1‑B“). So erhält das IT‑Team sofort eine korrekte Klärung, während gleichzeitig ein Record der gegebenen Advice erhalten bleibt.
V. Strategische Implementierung: Was Sie Ihr Tech‑Team fragen sollten
RAG ist oft ein „strategischer Quick Win“, weil es sich in relativ kurzer Zeit – häufig innerhalb weniger Wochen – operationalisieren lässt, ohne bestehende Workflows zu stören. Damit das System jedoch den High‑Stakes regulatorischer Arbeit genügt, müssen Sie Ihren technischen Partnern/Vendoren die richtigen Fragen stellen.
Buy vs. Build und der Hosted‑Vorteil
Für nicht‑technische Organisationen ist es selten effizient, eine eigene RAG‑Architektur von Grund auf zu bauen. Zwar wächst die Anzahl generischer „Hosted RAG“‑Plattformen langsam, aber Systeme mit Fokus auf Regulatory Compliance sind nach wie vor selten.
Bei der Evaluation sollten Ihre Kernfragen u. a. sein:
- Data Residency: Wo genau werden unsere Daten gespeichert, und verbleiben sie innerhalb unserer Jurisdiktion?
- Model‑agnostische Architektur: Können wir das zugrunde liegende Modell (z. B. von GPT‑4 zu Claude oder zu einem spezialisierten Legal‑Model) tauschen, ohne die gesamte Bibliothek neu aufzubauen?
- Data Segregation: Respektiert das System bestehende Access Levels, sodass z. B. Junior‑Mitarbeitende keine sensitiven Executive‑Board‑Minutes abrufen können?
Warnung: „Garbage In, Garbage Out“
Die Qualität eines RAG‑Systems ist nur so gut wie seine „Golden Source“ – die Dokumentenbibliothek, die Sie bereitstellen. Wenn Ihre Ordner drei verschiedene Versionen derselben Policy enthalten, kann die KI eine veraltete Version abrufen. Die Implementierung muss daher mit einer Data‑Hygiene‑Phase starten: Duplikate entfernen, PDFs OCR‑/Text‑searchable machen und Dokumente mit Metadaten labeln (z. B. „Effective Date“, „Jurisdiction“), damit die Retrieval‑Engine die relevantesten Informationen priorisieren kann.
Human in the Loop
Wichtig ist: RAG ist ein Co‑Pilot, kein Ersatz für professionelles Judgment. Das System übernimmt das „Heavy Lifting“ von Retrieval und initialem Drafting. Das finale Sign‑off muss immer von einem Senior‑Consultant kommen, der die Zitate gegen das Source Material prüft. Behandeln Sie RAG als sophistizierten Research Assistant: Sie nutzen die Geschwindigkeit – und behalten die Accountability Ihres Rollenverständnisses.
VI. Fazit
Die Integration von Retrieval‑Augmented Generation markiert den Übergang von der experimentellen Phase der KI hin zu pragmatischer, hoch‑nützlicher Anwendung in der regulatorischen Compliance. Indem generative Power an verifizierbare, auditierbare Daten gekoppelt wird, schlägt RAG die Brücke zwischen Geschwindigkeit moderner Technologie und der Präzision, die das Recht verlangt.
Der Wettbewerbsvorteil in 2025 wird nicht bei denen liegen, die die cleversten Prompts schreiben, sondern bei denen, die ihre proprietären Daten so organisiert haben, dass sie für KI zugänglich sind. Während das regulatorische Umfeld weiter an Komplexität gewinnt, wird die Fähigkeit, sofort korrekte, zitierte Informationen zu liefern, zur neuen Baseline für Exzellenz.
Für alle, die starten wollen, ist der effektivste Weg, ein Hosted‑RAG‑System zunächst auf einem einzelnen, abgegrenzten Dataset zu pilotieren – z. B. ein konkretes Jurisdiktions‑Rulebook oder ein Set interner Controls. So lässt sich Value messbar demonstrieren, ohne das Risiko eines Full‑Scale‑Deployments.